


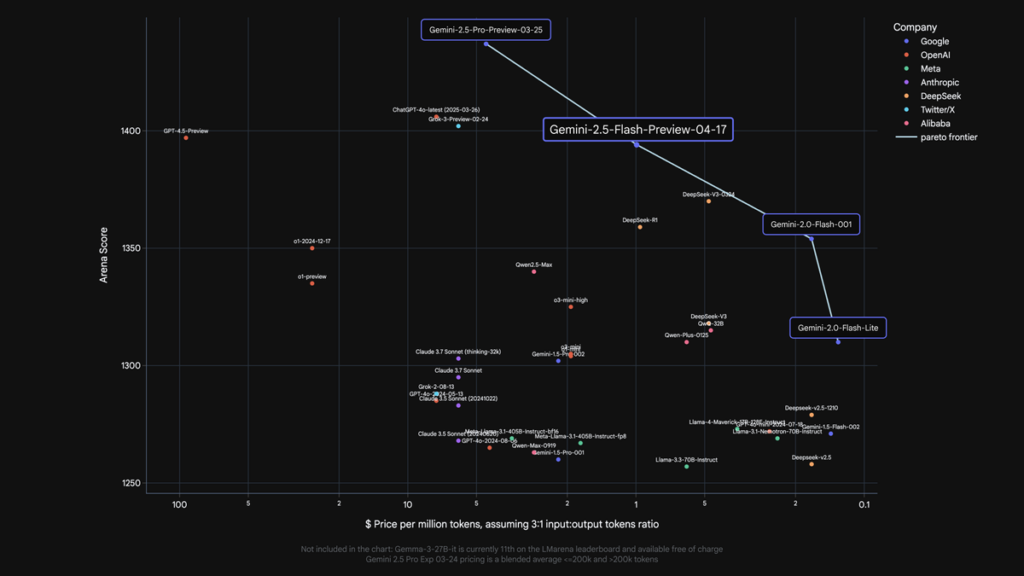
Google shipped its next-generation developer model, Gemini 2.5 Flash, on April 17, 2025, releasing it in preview through the Gemini API, Google AI Studio, Vertex AI, and a dropdown inside the Gemini app. Built for teams that need high-volume chat or real-time synthesis, the model maintains the latency of 2.0 Flash yet adds an optional reasoning stage that developers can toggle or cap—Google’s first hybrid reasoning model.
Gemini 2.5 Flash just dropped. ⚡
As a hybrid reasoning model, you can control how much it ‘thinks’ depending on your 💰 – making it ideal for tasks like building chat apps, extracting data and more.
Try an early version in @Google AI Studio → https://t.co/iZJNqQmooH pic.twitter.com/gUKbK5x3yZ
— Google DeepMind (@GoogleDeepMind) April 17, 2025
It is multimodal, supports a one-million-token context, and lets builders set a thinking_budget from 0-24,576 tokens. With reasoning enabled, it ranks just behind 2.5 Pro on the Hard Prompts benchmark. Input tokens cost $0.15 per million, while output costs scale from $0.60 (reasoning off) to $3.50 (reasoning on), providing a clear price-latency trade-off knob.
Early reactions from developers and analysts applaud the cost control and compare 2.5 Flash favorably with OpenAI’s o1 and DeepSeek’s R1, though they note quality tuning still requires careful evaluation.
Gemini 2.5 Flash extends Google’s tiered approach—Flash for cost-sensitive throughput, Pro for maximum quality—and will iterate in preview before general availability, according to the company’s release notes.