


A new benchmark from Artificial Analysis reveals alarming weaknesses in the factual reliability of large language models. Out of 40 models tested, only four achieved a positive score – with Google’s Gemini 3 Pro clearly in the lead.
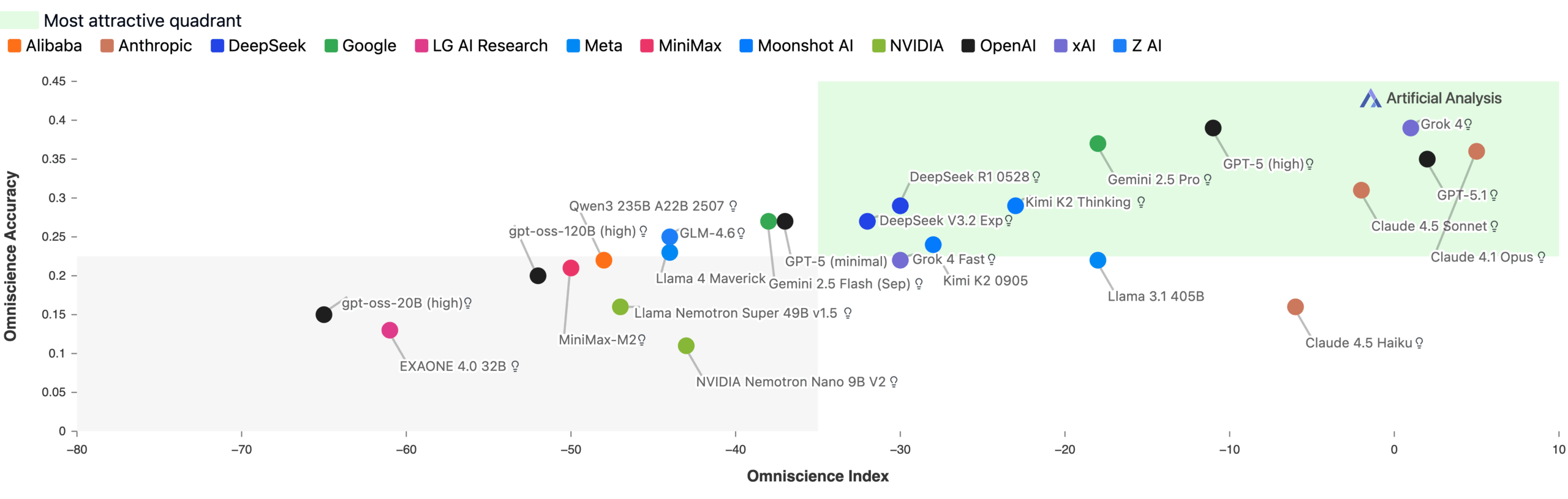
Gemini 3 Pro scored 13 points on the new Omniscience Index, which ranges from -100 to 100, substantially ahead of Claude 4.1 Opus (4.8), GPT-5.1, and Grok 4. The high score mainly reflects the model’s strong accuracy. Gemini 3 Pro outperformed Grok 4, the previously most accurate model, by 14 points. A score of 0 means a model answers questions correctly and incorrectly at the same rate. The AA-Omniscience Benchmark measures how reliably AI models retrieve factual knowledge across different subject areas.
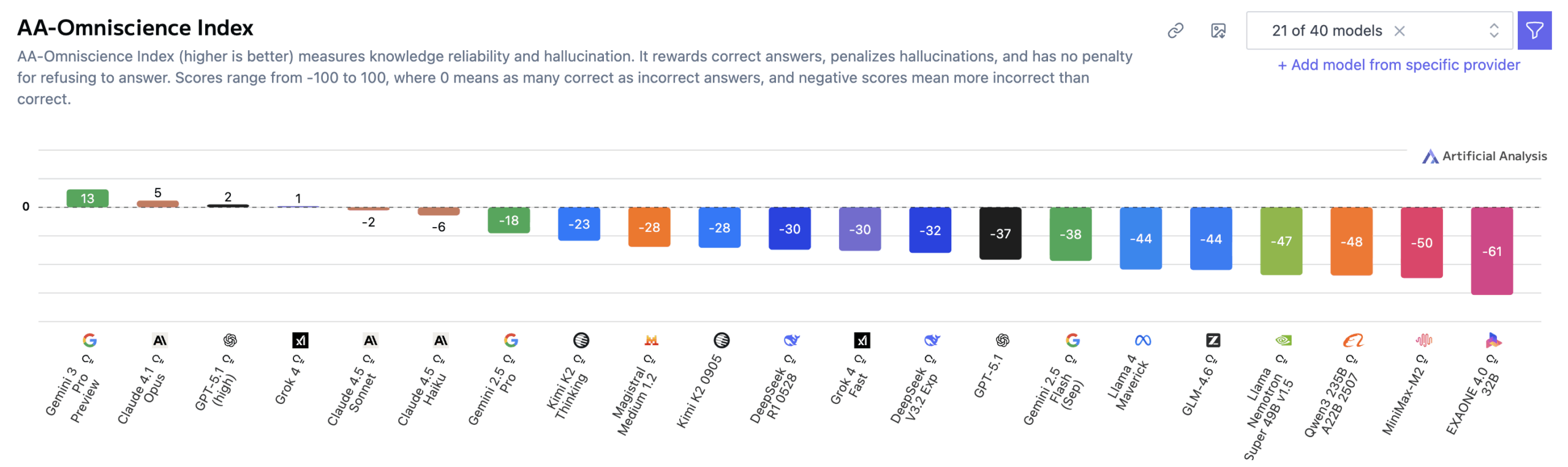
According to Artificial Analysis, Gemini 3 Pro’s lead is mainly driven by its increased accuracy – 14 points higher than Grok 4, the prior record-holder. The researchers interpret this as evidence of the model’s large scale since accuracy in the benchmark strongly correlates with model size.
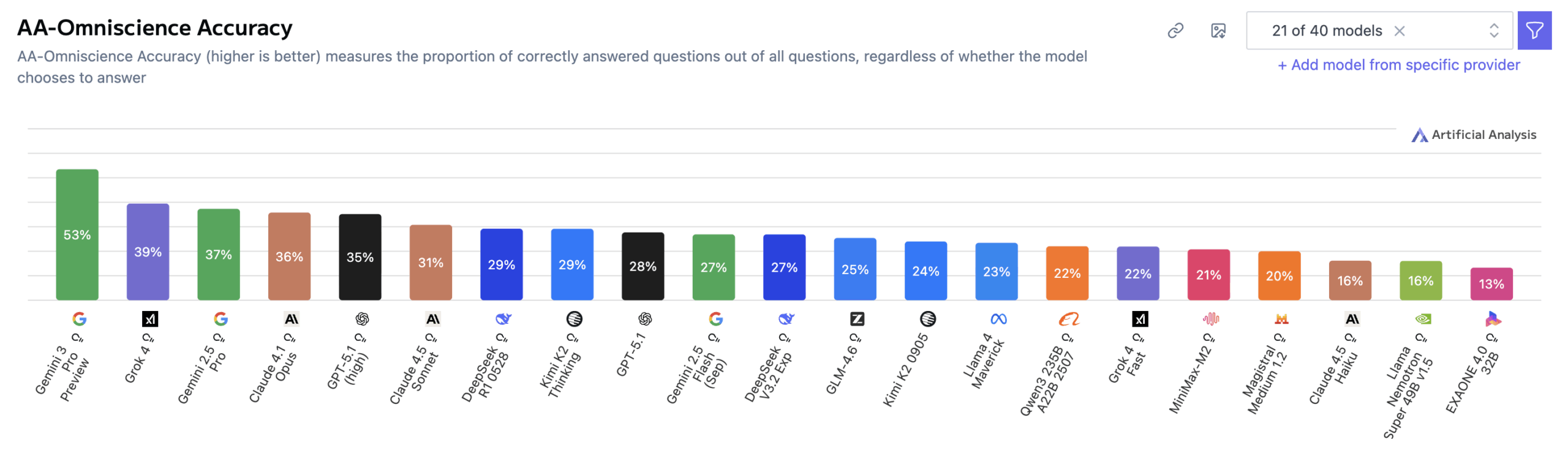
Hallucination rates remain the main weakness
The study found that poor results across the board stem largely from high hallucination rates. Gemini 3 Pro achieved the highest overall accuracy at 53 percent, far ahead of previous leaders like GPT‑5.1 (high) and Grok 4, both at 39 percent. But the model still showed an 88 percent hallucination rate, matching Gemini 2.5 Pro and Gemini 2.5 Flash.
Ad
GPT‑5.1 (high) and Grok 4 were also high at 81 and 64 percent respectively, but Gemini 3 Pro went even further. Artificial Analysis concluded that while Gemini 3 Pro demonstrates greater factual coverage, its tendency to give wrong answers rather than admit uncertainty remains unchanged.
Here, hallucination rate refers to the share of false responses among all incorrect attempts – meaning a high value indicates overconfidence, not ignorance.
Claude 4.1 Opus scored 36 percent accuracy with one of the lowest hallucination rates, giving it the top position before Gemini 3 Pro’s release.
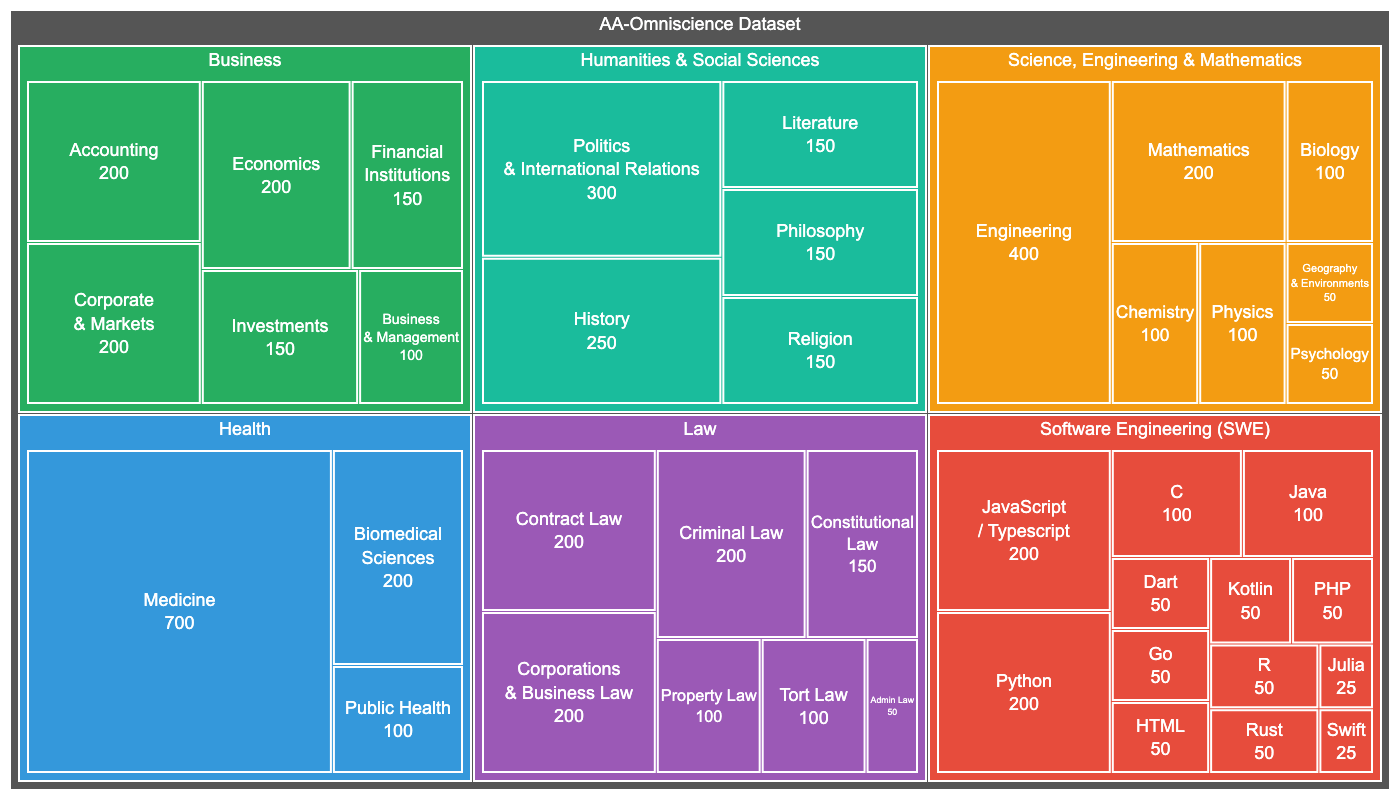
The AA-Omniscience benchmark covers 6,000 questions across 42 economically relevant topics in six domains: business, humanities and social sciences, health, law, software engineering, and science and math. The dataset draws from authoritative academic and industrial sources and was automatically generated by an AI agent.
A new scoring system that penalizes guessing
Unlike typical benchmarks, the Omniscience Index penalizes wrong answers as much as it rewards correct ones. The researchers argue that current evaluation methods often encourage guessing, which increases hallucination behavior.

{kind=link}
In contrast, the new metric rewards restraint. Models receive no points for admitting uncertainty, but they also aren’t penalized. Wrong answers, however, lead to large deductions.
The results group models into four categories: those with extensive knowledge and high reliability (like Claude 4.1 Opus), those with knowledge but low reliability (like Claude 4.5 Haiku), those with limited knowledge but consistent reliability (like GPT‑5.1), and finally, smaller models lacking both knowledge and reliability, such as OpenAI’s lightweight gpt‑oss.
No domain-specific breakdown was available for Gemini 3 Pro.
Older Llama model performs surprisingly well
General intelligence doesn’t necessarily translate into factual reliability. Models like Minimax M2 and gpt‑oss‑120b (high) perform strongly on the broader Artificial Analysis Intelligence Index, which aggregates results from multiple benchmarks, but do poorly on the Omniscience Index due to high hallucination rates.
Conversely, the older Llama‑3.1‑405B scored well on the Omniscience Index even though it typically ranks below newer frontier models in overall evaluations.
No single model demonstrated consistently strong factual reliability across all six domains. Claude 4.1 Opus led in law, software engineering, and the humanities; GPT‑5.1.1 ranked first in business questions; while Grok 4 performed best in health and science.
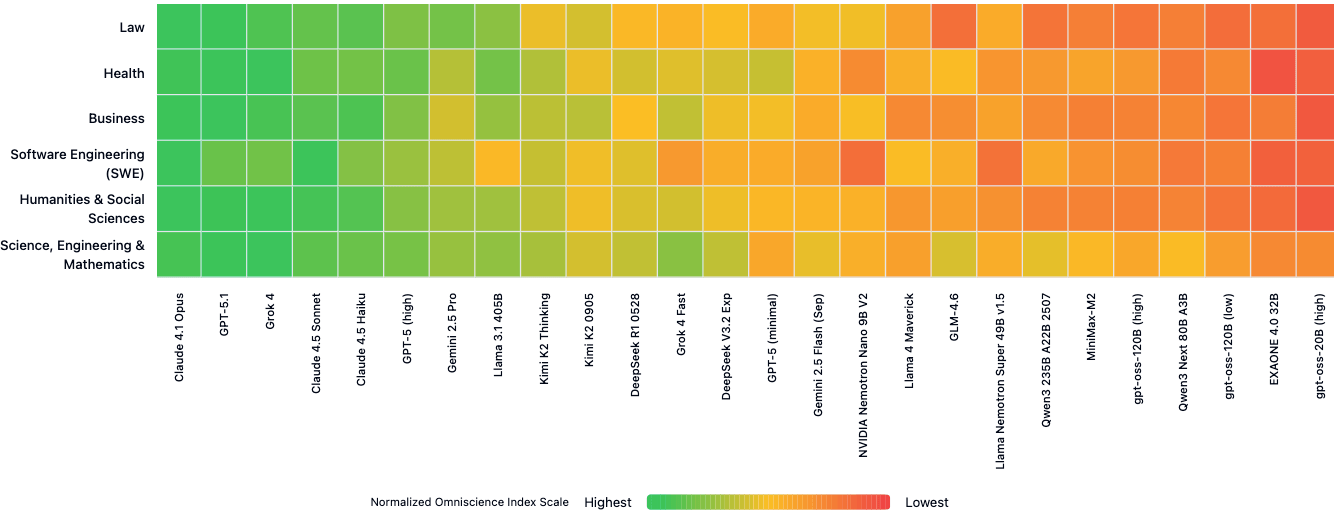
According to the study, these domain differences mean that relying solely on overall performance can obscure important gaps.
Bigger doesn’t always mean more reliable
While larger models tend to achieve higher accuracy, they don’t necessarily have lower hallucination rates. Several smaller models – like Nvidia’s Nemotron Nano 9B V2 and Llama Nemotron Super 49B v1.5 – outperformed much larger competitors on the Omniscience Index.
Artificial Analysis confirmed that accuracy strongly correlates with model size, but hallucination rate does not. That explains why Gemini 3 Pro, despite its high accuracy, still hallucinates frequently.
In terms of cost efficiency, Claude 4.5 Haiku stands out with a higher Omniscience score than several far more expensive models like GPT‑5.1 (high) and Kimi K2 Thinking.
The researchers have released 10 percent of the benchmark’s questions as a public dataset to support future research, while the majority remains private to prevent contamination of training data.
A related recent study uncovered structural flaws in existing AI benchmarks, citing vague definitions of key terms like “reasoning,” unrepresentative sampling, and a lack of statistical validation across model comparisons.